
Inleiding
 Van oudsher bestaat er een scherpe tegenstelling tussen de opvattingen van academici en professionals inzake de voorspelbaarheid van aandelenrendementen. Terwijl de meeste academici geloven dat aandelenkoersen nagenoeg onvoorspelbaar zijn, zijn veel professionals overtuigd van het bestaan van strategieën die een buy-and-hold portefeuille kunnen verslaan. Dit is overigens niet echt verwonderlijk, daar dit hun raison d’être is. Bovendien verdienen zij aan alle transactiekosten en beheersvergoedingen die uit hun beleggingsadviezen voortkomen. De stelling dat rendementen nagenoeg onvoorspelbaar zijn vertaalt zich in de welbekende efficiënte markthypothese. Deze hypothese stelt dat alle relevante informatie in de koersen verwerkt is en dat nieuwe informatie in financiële markten onmiddellijk en correct verwerkt wordt. De belangrijkste implicatie van deze hypothese (zoals al decennia lang door Burton Malkiel wordt benadrukt1 ) is dat pogingen om de markt te verslaan zinloos zijn.
Van oudsher bestaat er een scherpe tegenstelling tussen de opvattingen van academici en professionals inzake de voorspelbaarheid van aandelenrendementen. Terwijl de meeste academici geloven dat aandelenkoersen nagenoeg onvoorspelbaar zijn, zijn veel professionals overtuigd van het bestaan van strategieën die een buy-and-hold portefeuille kunnen verslaan. Dit is overigens niet echt verwonderlijk, daar dit hun raison d’être is. Bovendien verdienen zij aan alle transactiekosten en beheersvergoedingen die uit hun beleggingsadviezen voortkomen. De stelling dat rendementen nagenoeg onvoorspelbaar zijn vertaalt zich in de welbekende efficiënte markthypothese. Deze hypothese stelt dat alle relevante informatie in de koersen verwerkt is en dat nieuwe informatie in financiële markten onmiddellijk en correct verwerkt wordt. De belangrijkste implicatie van deze hypothese (zoals al decennia lang door Burton Malkiel wordt benadrukt1 ) is dat pogingen om de markt te verslaan zinloos zijn.
Veel professionals voelen zich beledigd als academici het weer eens over de efficiënte markthypothese hebben. Vaak hoor je het commentaar dat marktefficiëntie een verzinsel is van verstokte professoren die zelf nooit een cent belegd hebben. De beruchte hypothese komt echter niet uit een ivoren toren, maar is de synthese van jarenlange empirische bevindingen. Een treffende illustratie is dat drie op de vier actieve beleggingsfondsen in de Verenigde Staten het op lange termijn slechter doen dan de marktindex. Zelfs met de meest complexe modellen blijft het voorspellen van aandelenkoersen vrijwel onmogelijk. Dit feit verklaart mede de populariteit van indexfondsen en - trackers in de Verenigde Staten, die ook in Nederland aan belangstelling winnen.
 Nadat in het laatste decennium van de vorige eeuw diverse artikelen van toonaangevende onderzoekers in wetenschappelijke tijdschriften verschenen, staat ook de hedendaagse academische wereld open voor (een beperkte mate van) voorspelbaarheid. In deze artikelen bleken onder andere strategieën gebaseerd op macro-economische en/of financiële indicatoren, zoals het dividendrendement, op langere termijn de markt te kunnen verslaan, zelfs als er rekening wordt gehouden met transactiekosten en short-sale restricties. Meer recentelijk worden door enkele onderzoekers weer vraagtekens geplaatst bij deze bevindingen. Zij beweren dat de gerapporteerde resultaten weinig stabiel zijn over de tijd en dat de gevonden voorspelbaarheid mede het gevolg is van data snooping en andere methodologische problemen. Data snooping wil zeggen dat zelfs in de afwezigheid van voorspelbaarheid, variabelen gevonden kunnen worden die voorspelkracht lijken te bezitten. Door historisch toeval bestaat er binnen een gegeven periode altijd wel een verband tussen rendementen en één of meer indicatoren. Aan de andere kant worden in wetenschappelijke artikelen gerapporteerde technieken en patronen tegenwoordig regelmatig gebruikt door professionele beleggers. Een voorbeeld hiervan is de ‘Ratio Invest Fund’ van ABN AMRO, dat gebruik maakt van de wetenschappelijke bevindingen op het gebied van het zogenaamd overreactieeffect.
Nadat in het laatste decennium van de vorige eeuw diverse artikelen van toonaangevende onderzoekers in wetenschappelijke tijdschriften verschenen, staat ook de hedendaagse academische wereld open voor (een beperkte mate van) voorspelbaarheid. In deze artikelen bleken onder andere strategieën gebaseerd op macro-economische en/of financiële indicatoren, zoals het dividendrendement, op langere termijn de markt te kunnen verslaan, zelfs als er rekening wordt gehouden met transactiekosten en short-sale restricties. Meer recentelijk worden door enkele onderzoekers weer vraagtekens geplaatst bij deze bevindingen. Zij beweren dat de gerapporteerde resultaten weinig stabiel zijn over de tijd en dat de gevonden voorspelbaarheid mede het gevolg is van data snooping en andere methodologische problemen. Data snooping wil zeggen dat zelfs in de afwezigheid van voorspelbaarheid, variabelen gevonden kunnen worden die voorspelkracht lijken te bezitten. Door historisch toeval bestaat er binnen een gegeven periode altijd wel een verband tussen rendementen en één of meer indicatoren. Aan de andere kant worden in wetenschappelijke artikelen gerapporteerde technieken en patronen tegenwoordig regelmatig gebruikt door professionele beleggers. Een voorbeeld hiervan is de ‘Ratio Invest Fund’ van ABN AMRO, dat gebruik maakt van de wetenschappelijke bevindingen op het gebied van het zogenaamd overreactieeffect.
In dit artikel analyseren we de voorspelbaarheid van het rendement op de S&P 500 index over de laatste veertig jaar. Daarnaast beschouwen we ook voorspellingen voor de volatiliteit (gedefinieerd als de variantie van het rendement). Voor beide voorspellingen wordt gebruikt gemaakt van modellen waarin diverse macro-economische en financiële indicatoren als verklarende factoren worden opgenomen. Op basis van de rendements- en volatiliteitsvoorspellingen wordt getoetst op de aanwezigheid van market timing. Ons voornaamste doel is te onderzoeken of de voorspelkracht van het model met macro-economische en financiële variabelen afgenomen is sinds het bekend is geworden.
De Voorspelbaarheid van de S&P 500
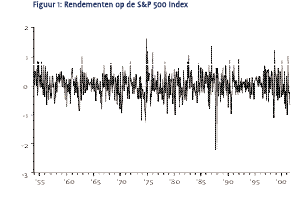
De maandelijkse rendementen van de S&P 500 index over de periode januari 1954 – augustus 2001 zijn weergegeven in Figuur 1. De beurskrach van oktober 1987, met een daling van meer dan 20%, springt het meest in het oog.
Om de rendementen te voorspellen, baseren we ons op de benadering van Pesaran en Timermann (1995)2, waarbij we uitgaan van een lineair model waarin een aantal macro-economische en financiële variabelen is opgenomen, d.w.z.

In vergelijking (1) is re t+1 het rendement op de S&P 500 index bovenop het risicovrije rendement (het exces rendement), terwijl Xt een fector is die de volgende macro-economische en financiële variabelen bevat: de koers-winst verhouding en het dividendrendement van de S&P 500, inflatie, industriële productie, korte en lange rente, de groei in de geldvoorraad en de junk bond spread (het verschil in de rente op een risicovolle bedrijfsobligatie en een staatsobligatie). Bovengenoemde variabelen zijn geselecteerd omdat deze reeds in de jaren 40 en 50 gesuggereerd werden in diverse studies.3 Deze variabelen worden vertraagd in het regressiemodel opgenomen. We verkrijgen voorspellingen door de onbekende coëfficiënten in β te schatten met OLS, gebruik makend van een expanding window (ofwel recursieve OLS). Doordat de modellen steeds geschat worden op basis van de op dat moment beschikbare gegevens, wordt bij het creëren van de voorspellingen uitsluitend gebruik gemaakt van werkelijk beschikbare informatie.
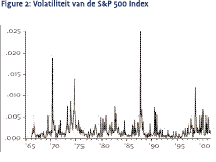 In Figuur 2 is de volatiliteit van het rendement op de S&P 500 index weergegeven, waarbij we gebruik maken van de dagelijkse schommelingen binnen een maand om de gerealiseerde volatiliteit te bepalen. Kenmerkend in deze figuur is het verschijnsel dat rustige en turbulente perioden elkaar afwisselen. Dit fenomeen wordt vaak aangeduid met de term volatility clustering. Een belangrijke implicatie voor beleggers is dat de ontwikkeling van de volatiliteit over de tijd tot op zekere hoogte voorspelbaar is. Een hoge volatiliteit vandaag wordt veelal gevolgd door een hoge volatiliteit morgen. Van deze eigenschap maken we gebruik in ons volatiliteitsmodel, waarin we de volatiliteit voorspellen aan de hand van de vertraagde volatiliteit en de korte rente:
In Figuur 2 is de volatiliteit van het rendement op de S&P 500 index weergegeven, waarbij we gebruik maken van de dagelijkse schommelingen binnen een maand om de gerealiseerde volatiliteit te bepalen. Kenmerkend in deze figuur is het verschijnsel dat rustige en turbulente perioden elkaar afwisselen. Dit fenomeen wordt vaak aangeduid met de term volatility clustering. Een belangrijke implicatie voor beleggers is dat de ontwikkeling van de volatiliteit over de tijd tot op zekere hoogte voorspelbaar is. Een hoge volatiliteit vandaag wordt veelal gevolgd door een hoge volatiliteit morgen. Van deze eigenschap maken we gebruik in ons volatiliteitsmodel, waarin we de volatiliteit voorspellen aan de hand van de vertraagde volatiliteit en de korte rente:

waarbij e2 t+1 de gekwadrateerde residuen uit (1) zijn en Zt de vertraagde gekwadrateerde residuen en de korte rente bevat. Model (2) is gebaseerd op het model in Breen, Glosten en Jagannathan (1989)4 en wordt ook recursief geschat.
 Op basis van het rendementsmodel worden voorspellingen gegenereerd voor het exces rendement op de S&P 500 index voor de periode januari 1960 tot en met augustus 2001.5 Op vergelijkbare wijze worden voorspellingen voor de volatiliteit gegenereerd. Deze voorspellingen worden vergeleken met de gerealiseerde waarden. Tabel 1 bevat een kruistabel waarin het teken van het voorspelde exces rendement wordt vergeleken met het werkelijk gerealiseerde exces rendement. We zien bijvoorbeeld dat het model in 173 maanden een positief exces rendement voorspelt, terwijl dat ook in werkelijkheid zo was. In 108 maanden wordt een positief exces rendement voorspeld, maar is de realisatie negatief. De hit ratio, het percentage correcte voorspellingen, is 56,2%.
Op basis van het rendementsmodel worden voorspellingen gegenereerd voor het exces rendement op de S&P 500 index voor de periode januari 1960 tot en met augustus 2001.5 Op vergelijkbare wijze worden voorspellingen voor de volatiliteit gegenereerd. Deze voorspellingen worden vergeleken met de gerealiseerde waarden. Tabel 1 bevat een kruistabel waarin het teken van het voorspelde exces rendement wordt vergeleken met het werkelijk gerealiseerde exces rendement. We zien bijvoorbeeld dat het model in 173 maanden een positief exces rendement voorspelt, terwijl dat ook in werkelijkheid zo was. In 108 maanden wordt een positief exces rendement voorspeld, maar is de realisatie negatief. De hit ratio, het percentage correcte voorspellingen, is 56,2%.
 In Tabel 2 staat een soortgelijke kruistabel voor de volatiliteitsvoorspellingen. Hoge en lage volatiliteit betekent hier respectievelijk hoger en lager dan de mediaan. De hit ratio van het volatiliteitsmodel is 58,9%. Aangezien beide hit ratio’s groter zijn dan 50%, lijkt het er op dat de modellen succesvol zijn. Een meer formele test hierop is de HenrikssonMerton test. Deze toets gaat na of het voorspellingsmodel significant betere resultaten geeft dan een model zonder enige voorspelkracht. Gezien het feit dat de realisaties de kritieke waarde van 1,64 (corresponderend met een betrouwbaarheid van 95%) overschrijden, kunnen we concluderen dat zowel het model voor de rendementen als het model voor de volatiliteit significante market timing bezit.
In Tabel 2 staat een soortgelijke kruistabel voor de volatiliteitsvoorspellingen. Hoge en lage volatiliteit betekent hier respectievelijk hoger en lager dan de mediaan. De hit ratio van het volatiliteitsmodel is 58,9%. Aangezien beide hit ratio’s groter zijn dan 50%, lijkt het er op dat de modellen succesvol zijn. Een meer formele test hierop is de HenrikssonMerton test. Deze toets gaat na of het voorspellingsmodel significant betere resultaten geeft dan een model zonder enige voorspelkracht. Gezien het feit dat de realisaties de kritieke waarde van 1,64 (corresponderend met een betrouwbaarheid van 95%) overschrijden, kunnen we concluderen dat zowel het model voor de rendementen als het model voor de volatiliteit significante market timing bezit.
Aan de hand van beide voorspellingsmodellen leiden we een aantal beleggingsstrategieën af. We veronderstellen dat een belegger alleen in aandelen (S&P 500) en een vastrentende waarde (3-maands staatsobligatie) kan beleggen. Strategie I is de ex ante optimale strategie (op basis van een mean-variance nutsfunctie), waarbij de strategie alleen rekening houdt met de voorspelde rendementen. Strategie II is een optimale beleggingsstrategie waarbij ook de voorspelde variantie invloed heeft op de beleggingsbeslissing. Bij een hoge (lage) voorspelde variantie, is het portefeuillegewicht in aandelen kleiner (groter). Strategie III en IV komen respectievelijk overeen met Strategie I en II, waarbij we opleggen dat de gewichten tussen 0 en 1 moeten liggen, met ander woorden we leggen short-sale beperkingen op. 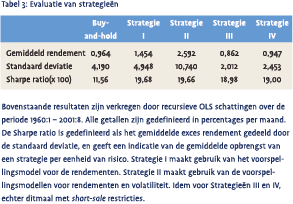 We vergelijken deze vier strategieën met elkaar en met een buy-andhold portefeuille, waarbij altijd het hele vermogen in aandelen is belegd. De resultaten in Tabel 3 laten zien dat alle vier de actieve strategieën een hoger rendement opleveren dan de passieve buy-and-hold strategie. Het gemiddeld rendement op de S&P 500 index tussen 1960 en 2001 is 0,96% per maand, hetgeen overeenkomt met zo’n 12% op jaarbasis. De strategie met het hoogste gemiddeld rendement maakt gebruik van de voorspelbaarheid in rendementen en volatiliteit, zonder short-sale restricties, en levert een jaarlijks rendement op van maar liefst 31%. Het risico dat hiermee gepaard gaat is echter substantieel groter dan dat van de buy-and-hold strategie. We mogen dus niet zomaar gerealiseerde rendementen met elkaar vergelijken. De Sharpe ratio geeft de mogelijkheid om strategieën met een verschillende risicograad met elkaar te vergelijken. De Sharpe ratio’s in Tabel 2 laten zien dat nog steeds iedere dynamische strategie het beter doet dan de passieve. Het lijkt dus raadzaam een dynamische strategie te gebruiken. Indien we de vier strategieën onderling vergelijken valt op dat Strategie I het hoogste rendement oplevert per eenheid risico, op de voet gevolgd door Strategie II. Doordat Strategie II af en toe extreme gewichten impliceert is de standaard deviatie een stuk hoger dan die van Strategie I. Indien we short-salerestricties opleggen – een modale belegger kan immers niet eenvoudig geld lenen om te beleggen – blijkt dat de Sharpe ratio’s iets kleiner worden en dat strategie IV, die rekening houdt met rendementen en volatiliteit, superieur is.
We vergelijken deze vier strategieën met elkaar en met een buy-andhold portefeuille, waarbij altijd het hele vermogen in aandelen is belegd. De resultaten in Tabel 3 laten zien dat alle vier de actieve strategieën een hoger rendement opleveren dan de passieve buy-and-hold strategie. Het gemiddeld rendement op de S&P 500 index tussen 1960 en 2001 is 0,96% per maand, hetgeen overeenkomt met zo’n 12% op jaarbasis. De strategie met het hoogste gemiddeld rendement maakt gebruik van de voorspelbaarheid in rendementen en volatiliteit, zonder short-sale restricties, en levert een jaarlijks rendement op van maar liefst 31%. Het risico dat hiermee gepaard gaat is echter substantieel groter dan dat van de buy-and-hold strategie. We mogen dus niet zomaar gerealiseerde rendementen met elkaar vergelijken. De Sharpe ratio geeft de mogelijkheid om strategieën met een verschillende risicograad met elkaar te vergelijken. De Sharpe ratio’s in Tabel 2 laten zien dat nog steeds iedere dynamische strategie het beter doet dan de passieve. Het lijkt dus raadzaam een dynamische strategie te gebruiken. Indien we de vier strategieën onderling vergelijken valt op dat Strategie I het hoogste rendement oplevert per eenheid risico, op de voet gevolgd door Strategie II. Doordat Strategie II af en toe extreme gewichten impliceert is de standaard deviatie een stuk hoger dan die van Strategie I. Indien we short-salerestricties opleggen – een modale belegger kan immers niet eenvoudig geld lenen om te beleggen – blijkt dat de Sharpe ratio’s iets kleiner worden en dat strategie IV, die rekening houdt met rendementen en volatiliteit, superieur is.
Is de voorspelbaarheid echt?
Op basis van bovenstaande bevindingen lijkt het erop dat we redelijk eenvoudig de markt kunnen verslaan. Echter, met een aantal zaken is geen rekening gehouden. Ten eerste zullen transactiekosten voor dynamische strategieën een stuk groter zijn dan voor een passieve strategie. Wanneer we bovenstaande strategieën doorrekenen, rekening houdend met transactiekosten, dan verslaan de actieve strategieën nog steeds de passieve, zelfs voor relatief hoge transactiekosten van 1%. Ten tweede overschat de Sharpe ratio het risico in geval van volatility timing, dus voor Strategie II en IV. Daarom hebben Marquering en Verbeek (2003)6 een andere maatstaf gebruikt om de performance van beleggingsstrategieën te meten, gebaseerd op een nutsfunctie, waarbij de volatiliteit bepaald wordt gebruikmakend van dagelijkse data.
Recent onderzoek toont aan dat dit leidt tot een meer correcte performancemeting, waarbij het probleem van overschatting van het risico wordt verholpen. Gebruikmakend van deze methode blijkt dat de transactiekosten 1,3% of hoger moeten zijn opdat de dynamische strategie niet meer superieur is, en zelfs 1,5% voor de strategie met volatiliteitvoorspellingen.
Tenslotte moeten we ons er van bewust zijn dat de resultaten ‘besmet’ kunnen zijn met data snooping. Indien de gevonden voorspelkracht grotendeels gebaseerd is op historische toevalligheden, gevonden na een uitgebreide zoektocht over mogelijke voorspellende indicatoren, dan heeft het model weinig werkelijke voorspellende waarde. In zo’n geval kan verwacht worden dat we in de toekomst minder sterke resultaten vinden, en kan de voorspelbaarheid zelfs helemaal verdwijnen.7 Hiermee samenhangend is het verschijnsel dat een strategie zichzelf dreigt te vernietigen zodra deze erg bekend wordt in de financiële wereld. Dit is (waarschijnlijk) het geval geweest met bijvoorbeeld het januari-effect (rendementen zijn gemiddeld genomen het hoogst in de maand januari), het ‘small-firm’ effect (aandelen van kleine bedrijven doen het beter dan die van grote, zelfs na risicocorrectie) en het ‘turn-of-the-month’ effect (rendementen zijn in het algemeen relatief hoog aan het einde en begin van elke maand). Dit wordt soms aangeduid met de wet van Murphy in de financiële wereld.8 Zoals een sneetje brood altijd met de beboterde kant op de grond valt, zal een strategie die tracht te profiteren van voorspelbaarheid gedoemd zijn te mislukken als je het probeert toe te passen in de praktijk. Mogelijkerwijs verdwijnt de voorspelbaarheid doordat meer beleggers handelen op basis van de specifieke anomalie. Doordat bovendien beleggers slim handelen en anderen proberen voor te zijn, zal de anomalie gedeeltelijk of geheel verdwijnen.
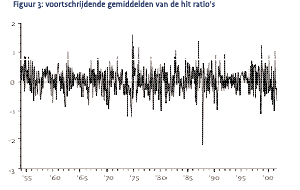 Om te onderzoeken of de voorspelkracht afgenomen is over de laatste jaren, beschouwen we Figuur 3, waarin de 5-jaarlijkse voortschrijdende gemiddelden van de hit ratio’s van het rendement en de volatiliteit worden weergegeven. Deze geven de proporties van correct voorspelde tekens over de afgelopen vijf jaren weer. De figuur laat zien dat beide hit ratio’s zich vaker boven dan onder de 0,5 bevinden. Indien de hit ratio boven de horizontale stippellijn ligt, wil dat zeggen dat market timing statistisch significant is. Wat direct opvalt is dat de ratio’s niet erg constant zijn over de tijd. Eind jaren zeventig, bijvoorbeeld, bleken rendement en volatiliteit vrij moeilijk te voorspellen. Een tweede dat opvalt is de scherpe daling in de hit ratio van de volatiliteit in 1983 en die van de rendementen in 1995. Toevallig of niet, rond die tijd zijn juist de eerste en meest invloedrijke onderzoeken omtrent het voorspellen van respectievelijk volatiliteit en rendementen9 in de literatuur verschenen. De wet van Murpy komt blijkbaar ook hier weer om de hoek kijken. Echter, na een lange periode van relatief zwakke voorspelbaarheid in de volatiliteit lijkt de voorspelkracht zich weer te herstellen in de laatste vijf jaar. Voor het voorspellen van de rendementen waren de laatste vijf jaar belabberd. Het feit dat de tweede helft van de jaren negentig vanwege de internetbubbel veel meer positieve dan negatieve exces rendementen kende, kan wellicht mede de slechte performance van het voorspellingsmodel verklaren. Of de rendementen zich in de toekomst weer beter laten voorspellen moet de toekomst uitwijzen. Als de beurskoersen inderdaad voorspelbaar zijn, en dit is niet het resultaat van data snooping, lijkt het verstandig voor ontdekkers van nieuwe strategieën ze voorlopig niet publiekelijk bekend te maken.
Om te onderzoeken of de voorspelkracht afgenomen is over de laatste jaren, beschouwen we Figuur 3, waarin de 5-jaarlijkse voortschrijdende gemiddelden van de hit ratio’s van het rendement en de volatiliteit worden weergegeven. Deze geven de proporties van correct voorspelde tekens over de afgelopen vijf jaren weer. De figuur laat zien dat beide hit ratio’s zich vaker boven dan onder de 0,5 bevinden. Indien de hit ratio boven de horizontale stippellijn ligt, wil dat zeggen dat market timing statistisch significant is. Wat direct opvalt is dat de ratio’s niet erg constant zijn over de tijd. Eind jaren zeventig, bijvoorbeeld, bleken rendement en volatiliteit vrij moeilijk te voorspellen. Een tweede dat opvalt is de scherpe daling in de hit ratio van de volatiliteit in 1983 en die van de rendementen in 1995. Toevallig of niet, rond die tijd zijn juist de eerste en meest invloedrijke onderzoeken omtrent het voorspellen van respectievelijk volatiliteit en rendementen9 in de literatuur verschenen. De wet van Murpy komt blijkbaar ook hier weer om de hoek kijken. Echter, na een lange periode van relatief zwakke voorspelbaarheid in de volatiliteit lijkt de voorspelkracht zich weer te herstellen in de laatste vijf jaar. Voor het voorspellen van de rendementen waren de laatste vijf jaar belabberd. Het feit dat de tweede helft van de jaren negentig vanwege de internetbubbel veel meer positieve dan negatieve exces rendementen kende, kan wellicht mede de slechte performance van het voorspellingsmodel verklaren. Of de rendementen zich in de toekomst weer beter laten voorspellen moet de toekomst uitwijzen. Als de beurskoersen inderdaad voorspelbaar zijn, en dit is niet het resultaat van data snooping, lijkt het verstandig voor ontdekkers van nieuwe strategieën ze voorlopig niet publiekelijk bekend te maken.
Conclusies
In dit artikel is de voorspelbaarheid van rendementen en volatiliteit van de S&P 500 index bestudeerd aan de hand van macro-economische en financiële variabelen. Het blijkt dat beide reeksen tot op zekere hoogte voorspelbaar zijn. Zelfs na het opleggen van short-sale beperkingen en transactiekosten, blijven actieve beleggingsstrategieën het beter doen dan een buy-and-hold portefeuille. Vanaf 1995 is echter de voorspelbaarheid in rendementen dramatisch gedaald. Een mogelijke verklaring hiervoor is dezelfde die dikwijls wordt aangedragen voor het verdwijnen van het januari effect, het ‘small-firm’ effect en het ‘turn-of-the-month’ effect: zodra een strategie bekend wordt in de financiële wereld dreigt deze zichzelf te vernietigen. Voor beleggers die proberen van voorspelbaarheid te profiteren valt het brood meestal met de beboterde kant op de grond. Deze wet van Murphy treedt mogelijk op vanwege data snooping en de zelfvernietigende eigenschap van beleggingsstrategieën. En dit wordt weer mooi samengevat in de tweede wet van Murphy: ‘Nothing is ever as simple as it seems’.
Noten
- Zie B.G. Malkiel, 1999, A Random Walk Down Wall Street, 7de editie, Norton.
- Pesaran M. en A. Timmermann, 1995, ‘Predictability of Stock Returns: Robustness and Economic Significance’, Journal of Finance, 50, 1201-1228.
- Voor een overzicht: zie Pesaran en Timermann (1995).
- Breen, W., L.R. Glosten en R. Jagannthan, 1989, ‘Economic Significance of Predictable Variations in Stock Index Returns’, Journal of Finance, 44, 1177-1189.
- We gebruiken de data van Pesaran en Timmermann (1995) en breiden hun tijdspanne uit van 1992 tot 2001.
- Marquering W. en M. Verbeek, 2003, ‘The Economic Value of Predicting Stock Index Returns and Volatility’, Journal of Financial and Quantitative Analysis, te verschijnen.
- We hebben in dit onderzoek zo veel mogelijk getracht het verschijnsel data snooping te ondervangen, maar helemaal vrijuit kunnen we nooit gaan.
- Dimson E. en P. Marsh, 1999, ‘Murphy’s Law and Market Anomalies’, Journal of Portfolio Management, 25, 53-69.
- Pesaran M. en A. Timmermann, 1995, ‘Predictability of Stock Returns: Robustness and Economic Significance’, Journal of Finance, 50, 1201-1228.
Nawoord
De auteurs danken Hans de Ruiter, Philip Stork en de referenten voor hun commentaar en suggesties.
in VBA Journaal door Wessel Marquering (l) en Marno Verbeek (r)